
IA en formation : modalités “text-to-image” & “image-to-text” L’essor des outils d’IA transforme les pratiques pédagogiques, offrant de nouvelles façons d’enseigner et d’apprendre. Cette capsule explore deux modalités, “text-to-image” et … Poursuivre la lecture “IA en formation – atelier découverte I”

Philippe Piekoszewski-Cuq, enseignant de technologie, formateur DRANE dans l’académie de Caen, propose un guide pratique pour les enseignants, plutôt de l’Éducation Nationale et à destinant d’élèves du secondaire. Il est … Poursuivre la lecture “Intelligence artificielle : guide pratique pour les enseignants”

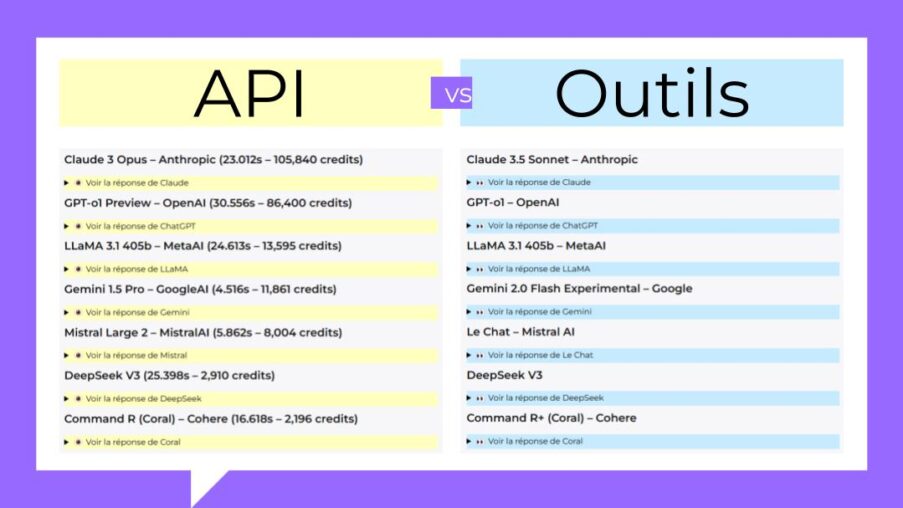
Ce petit comparatif a pour objectif de faire un très rapide état des lieux des principaux outils d’IA génératives à disposition du grand public actuellement (mi-janvier 2025). Dans un premier … Poursuivre la lecture “Comparatif d’outils d’IA génératives”

Une présentation réalisée dans de le cadre d’une Journée Thématique sur le numérique et l’intelligence artificielle en éducation. De nombreux liens et ressources sont accessibles dans la présentation, explorez-les dans … Poursuivre la lecture “Intelligence Artificielle : quel usage pédagogique ?”

Dans la suite de l’Abécédaire de l’IA de l’Obvia (2024) voici la version 2025 du glossaire évolutif mis à jour avec de nouvelles définitions relatives aux fondements de l’intelligence artificielle … Poursuivre la lecture “Glossaire de l’Obvia”

Avignon Université, via la mission APUI, propose deux cours en ligne, l’un à destination des enseignants et l’autre des étudiants, pour mieux comprendre l’IA et ses usages dans l’enseignement supérieur. … Poursuivre la lecture “Cours : IA dans l’enseignement supérieur”

Face à l’émergence de l’IA générative (IAG), ce document propose des clés pour les enseignant·es de l’enseignement supérieur afin de s’approprier cet outil et analyser son impact potentiel sur leurs … Poursuivre la lecture “Les Clés du LLL – Intégrer l’IA générative dans les stratégies pédagogiques”
Vendredi 6 décembre, 10h-12h (en Français) : Présentation et discussion sur l’utilisation d’outils GenAI (Generative AI) à des fins de recherche proposée par Carolina SERRANO ARCHIMI, une collègue AMU de l’IAE Aix, tech- enthousiaste mais pas tech-experte – … Poursuivre la lecture “Utiliser l’IA à des fins de recherche”

En deux ans, les établissements académiques ont-ils (vraiment) réussi s’adapter aux IA génératives ? Telle est la question posée par Compilatio, l’entreprise spécialisée dans la prévention et la détection du … Poursuivre la lecture “Compilatio : 4 mini-conférences d’experts autour des IA génératives”
Intervenant Frédéric Agnès et Mélissa Toye de Compilatio Comment transformer chaque étape du processus d’évaluation avec des solutions d’IA novatrices ? Découvrir Gingo : votre futur assistant à la correction … Poursuivre la lecture “L’IA au service de l’évaluation des étudiants et de la correction des travaux”
Intervenant Yves Moreau Fonction de l’intervenant Docteur en Histoire, Ingénieur pour l’enseignement numérique et référent plagiat à l’Université Jean Moulin Lyon 3 Un établissement déjà sensibilisé aux problématiques liées au … Poursuivre la lecture “La mise en place d’une politique de prévention sur les IA génératives à l’université Jean Moulin Lyon 3 : retour d’expérience”

Un support a été créé par les bibliothécaires d’AMU qui met en avant les enjeux et les perspectives des outils d’IA sous le prisme des compétences informationnelles, tout en incluant une … Poursuivre la lecture “Intelligence artificielle générative : une introduction”
Ce webinaire, organisé par le GTnum #IA2GE – IA génératives et grands modèles de langage conversationnels et/ou multimodaux dans les établissements scolaires du Grand-Est – est destiné aux personnels de … Poursuivre la lecture “IA générative et évaluation pédagogique : webinaire du GTnum #IA2GE”
Intervenant Guy Mamou-Mani Fonction de l’intervenant Ex co-Président d’Open Ex Président Numeum, Ex vice Président du CNNNum, Enseignant en écoles de commerce et SciencesPo, Business Angel, Administrateur ThinkTank: Impact AI, … Poursuivre la lecture ““Le futur n’est pas ce qui va arriver mais ce que nous en ferons” Bergson”
Intervenant Jean-François Van de Poël Fonction de l’intervenant Adjoint Digital Learning auprès du Centre de Soutien à l’Enseignement de l’Université de Lausanne Depuis toujours, notre écriture s’enrichit d’une variété de … Poursuivre la lecture “Mais non Jeff, t’es pas tout seul ! Écrire avec des Compagnons : De l’Oralité à l’IA, une Continuité vers l’Authenticité ?”
L’Artificial Intelligence Marseille (AIM), une journée pour décrypter les enjeux économiques, politiques, culturels et sociétaux autour de l’IA

L’utilisation du numérique dans le milieu scolaire doit d’abord viser à soutenir la réussite éducative et à assurer une gestion plus transparente et efficiente. Ce document de référence permet de … Poursuivre la lecture “Guide d’utilisation pédagogique, éthique et légale de l’intelligence artificielle générative”

En avril 2023, un premier webinaire avait été proposé sur les potentialités de l’intelligence artificielle (IA) en éducation. Depuis, de nombreux documents ont été publiés (CIQ, 2024 ; CSÉ, 2024 … Poursuivre la lecture “L’intelligence artificielle générative (IAG) en éducation”

Les dossiers thématiques de l’Obvia visent à valoriser le partage de connaissances, à renforcer les capacités individuelles et collectives et à mieux comprendre les impacts sociétaux de l’intelligence artificielle (IA) et du numérique.